You are in US.
It is 06:50 JST now.
IPv6時代のセキュリティ対策

サーバ管理者であれば、何らかのアクセス規制を導入していると思います。
その中でも頼りになるのが国別のIPリストではないでしょうか?
国別のIPリストを利用すれば「SSHの接続は国内限定にする」「特定の国からのアクセスを一括で規制する」といった対応が可能になります。
2017年現在IPv6の利用は、以下のグラフが示す通り、加速度的に増えています。
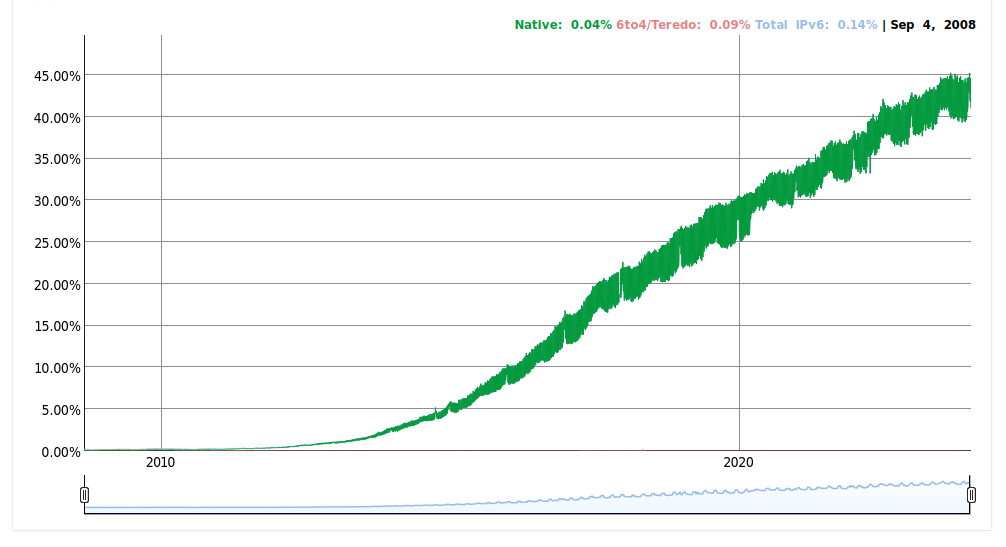
日本でも大手プロバイダやスマホでの利用で増加しており、40%を越えたといわれています。
Googleへのトラフィックが示す通り、世界中では2021年3月現在38%程度の機器がIPv6で接続されています。
アクセス規制というサーバの根幹に関わるリストを、いつ停止するとも限らないソースに委ねるというのは、大きなリスクになります。
また、日本では感性の異常差などで言われている『マスゴミ』『バカメディア』の作成した文章で
IPv4と違い、IPv6ではNATが使われない などいう事を平気で嘘を書いている。そのまま接続したら攻撃の嵐にさらされるのだ!!ちょっと古い(アップデートが終わった)スマホやWindowsが耐えられると思いますか????(実際、かなりの方々が被害を受けている)
fdxx: (xxは自由) から始まるIpv6プライベートアドレスが記述されておりNAT(正確にはMASQUERADE)接続が下記の様にIPv4同様に記述できる。さもIPv6がIPv4と「かなり違う」と書いている輩は理解していない(できない)だけで「文章を書くな!」と言いたくなってくる・・・・
IPv6
ip6table -t nat -A POSTROUTING -s fd00:cafe::/64 -j MASQUERADE
ipv4
iptable -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
のように記述すれば簡単に実現できる。IPv6もIPv4も殆ど変わらないのだ。当サイトの IPoE DS-Lite ルーター 作成記事も実例を上げている。情報が溢れる現在、それを精査するのは個人の責任であるのではないだろうか?
つまりIPv4とIPv6のセキュリティー対策は変わらないということである。MASQUERADEがLinuxで発明されて市販ルーターに採用され攻撃は激減されたが逆にIPv6直繋ぎで増えているのである。
セキュリティーの一環として自前で「国別IPv4とIPv6のIPアドレス割当リストを作ろう」というのがこれ以降の記述です。
目次
- IPv4のIPアドレス割当リストを作る上での留意点
- ipv4_cidr_client_01.php
- ipv4_cidr_client_02.php
- ipv4_cidr_client_03.php
- ipv6_cidr_client_01.php
- ipv6_cidr_client_02.php
IPv4のIPアドレス割当リストを作る上での留意点
上でも解説しましたが、IPのリストはRIR(地域インターネットレジストリ)で公表されています。
具体的には以下のアドレスです。
ftp://ftp.arin.net/pub/stats/arin/delegated-arin-extended-latest
ftp://ftp.ripe.net/pub/stats/ripencc/delegated-ripencc-extended-latest
ftp://ftp.apnic.net/pub/stats/apnic/delegated-apnic-extended-latest
ftp://ftp.lacnic.net/pub/stats/lacnic/delegated-lacnic-extended-latest
ftp://ftp.afrinic.net/pub/stats/afrinic/delegated-afrinic-extended-latest
これらのリストには「世界の国別 IPv4 アドレス割り当てリスト」で解説されているとおり、いくつか問題があります。
フォーマットはRIR statistics exchange format – APNICで定義されており以下の書式で公開されています。
|
1
|
registry|cc|type|start|value|date|status[|extensions...] |
サンプルで実例を示すと以下のようになっています。
|
1
|
afrinic|ZA|ipv4|169.159.128.0|16384|20160113|allocated|F3632FD4 |
必要なのはCCの部分で表現する国別コードです。
具体的には「ISO 3166-2」で定義された行政区画コードと呼ばれるものです。
続いてtypeの部分で「ipv4」か「ipv6」を識別します。
IPアドレスを示すのは開始アドレスである「start」と、IP数である「value」で表現されています。
問題点は以下のとおりです。
1.CIDR表記で割り切れない
valueの範囲をプレフィックスで表現するのですが、CIDR表記で割り切れる範囲とは限りません。
例えば範囲が「6144」となっている場合、「4096」と「2048」に分けて、「/20」と「/21」で表現する必要があります。
1.CIDR表記が細切れになっている
上のように分割しなければいけない項目がある反面、連続しているのに分割されている項目も存在します。ただでさえ長いリストなので、結合できる部分は結合します。
1.順序がバラバラ
リストを利用する際はプログラムで走査するので、そのままでも問題ありませんが、視覚的に把握しやすくするためソートします。
使い勝手の良いリストを作成するには、これらの問題を解決する必要があります。
サーバ用ということでBashでも良かったのですが、さくっと作りたかったので使い慣れたPHPで作成しました。
ipv4_cidr_client_01.php
まずはIPv4の国別リストを読み込みます。
RIRからリストを取得し、後処理のためにIPアドレスを長整数表現に変換し、ファイルに書き出します。
いくつかのファイルに分けるのは原因の切り分けが容易になるのと、メモリ消費を抑えるためです。
ファイル名や作成場所は環境に合わせて変えてください。
今回は「/usr/script」というディレクトリを作成してファイルを作成しました。
# mkdir /usr/script # cd /usr/script # vi ipv4_cidr_client_01.php
ソースを見ていただければわかると思いますが、作成されるリストや、製作途中のリストは/tmpディレクトリに保存されます。
ちなにみtmpディレクトリはデフォルトでファイルの作成から240時間経過すると削除されるためリスト作成の頻度には注意してください。
<?php /* * 1.IPのリストを取得 * * 2.後処理のためにIPアドレスを長整数表現に変換し * 国別コードと合わせて書き出す * */ |
見たままで特に解説するところもありませんが、メモリを節約するためファイルの読み込みにはSplFileObjectを利用しています。
setFlagsで空の行や最後の改行などを無視します。
ちなみにオブジェクトはそのままforeachで回せます。
この方法であればfopen()で開いてfgets()で読み込みfclose()で閉じるといった手間もかかりません。
またfile_get_contents()のように巨大なファイルを丸々メモリに載せる必要もありません。
ipv4_cidr_client_02.php
続いて国名とIPでソートします。
さらにサブネット部をCIDR表記で表現できる一番大きな値に分割します。
CIDR表記で割り切れるIPアドレス数は以下のサイトを参照してください。
サブネットマスク計算(IPv4)/サブネット一覧(早見表)
<?php
/**
* 1.リストをソートし国とIPが連続する場合結合
*
* 2.IPがCIDR形式(サブネットマスク形式)で割り切れない場合、
* CIDR形式で表現できるように分割するスクリプト
*
*/
define( 'TEMP_PATH', '/tmp' );
define( 'OLD_CIDR_LIST_PATH', TEMP_PATH . '/ipv4_cidr_01.txt' );
define( 'CIDR_LIST_PATH', TEMP_PATH . '/ipv4_cidr_02.txt' ); // 書き出すIPリスト
// IPリストをソートしてキーを振り直す
$lists = new SplFileObject(OLD_CIDR_LIST_PATH);
$lists->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
$arr = array();
foreach( $lists as $val ){
if ($val === false) continue;
$arr[] = $val;
}
asort($arr);
$arr = array_merge($arr);
// 国の名前が同じで、現在のip_maxと次のip_minが連続している場合結合する
$i = 0;
foreach ( $arr as $key => &$val ) {
if ( isset( $arr[$i + 1] ) ){
$j = explode( "\t", $val);
$k = explode( "\t", $arr[$i + 1]);
if (
$j[0] == $k[0] &&
$j[2] == $k[1] - 1
){
$arr[ $i + 1 ] = $j[0] . "\t" . $j[1] . "\t" . $k[2];
unset( $arr[$i] );
}
}
$i++;
}
unset($val); // 参照渡しのリセット
// $cidr_rangesにCIDR形式で使われる4から2147483648の倍数をセット
// 参照:https://note.cman.jp/network/subnetmask.cgi
$range = array();
for( $i = 0; $i < 30; $i++ ){
$ranges[] = pow( 2, $i + 2 );
}
$cidr_ranges = array_reverse( $ranges );
/**
* IPの範囲を調べる
* ip_range_cidr_splitへIPの範囲を渡してCIDR形式に分割し
* 新たなファイルに書き出す
*/
$wfp = fopen( CIDR_LIST_PATH, 'w' );
foreach( $arr as $key => $val ){
// IPのrangeの取得
if( ! empty( $val ) ){
$j = explode( "\t", $val );
$country = $j[0];
$ip_min = $j[1];
$ip_max = $j[2];
$ip_range = $ip_max - $ip_min + 1;
$split_lists = ip_range_cidr_split( $ip_range, $cidr_ranges );
foreach ( $split_lists as $row ) {
$ip_max = $ip_min + $row - 1;
fwrite( $wfp, $country . "\t" . $ip_min . "\t" . $ip_max . "\n" );
$ip_min = $ip_min + $row;
}
}
}
fclose( $wfp );
/**
* IPの範囲とCIDR表記で割り切れる値を渡すと
* CIDRで表現できるIPの範囲を配列で返す
*
* @param int IPの範囲
* @param arr CIDR表記で割り切れる値
* @return arr CIDRで表現できるIPの範囲を配列で返す
*/
function ip_range_cidr_split( $ip_range, $cidr_ranges ) {
$split_lists = array();
foreach( $cidr_ranges as $cidr_range ){
// $rangeで引いて、残りをもう一度この関数で処理(割り切れるまで実行)
if( $ip_range == $cidr_range ){ // 割り切れる場合は処理終了
$split_lists[] = $ip_range;
return $split_lists;
} elseif ( $ip_range > $cidr_range ){
$split_lists[] = $cidr_range;
$ip_range = $ip_range - $cidr_range;
}
}
return $split_lists;
}
|
割り切れる値に分割する理由は次の項目で解説します。
ipv4_cidr_client_03.php
下準備が終わったのでIPをCIDR表記に変換します。
関数PlageVersCIDRs()について
変換するためのスクリプトは以下のサイトのものを利用させていただきました。
http://php.net/manual/ja/ref.network.php#75922
ざっくり解説するとIPの開始(min)と終わり(max)の値を2進数に直し、minの後ろをカウンターを利用して1に置換し、maxの値になるまで比較。最終的なカウンターの値でプレフィックスを取得。
最後にlong2ipとbindecでデコードという流れです。
どうやったらこんなコードを閃くのか頭を覗いてみたいですねw
便利な関数なのですが、一つ問題点があります。比較の際にCIDR表記で割り切れる値で丸めてしまうため、端数を捨ててしまうという点です。
そのためにipv4_cidr_client_02.phpで割り切れる値に分割したというわけです。(他にも解決方法はたくさんありますが、一番最初に思いついた方法を採用しましたw)
ファイル作成の成否をメールで通知
リストを作成するにあたり、RIRのIPリストをWeb上から取得する以上、失敗することもあります。
そこで前回作成したリストと比較して、相違点が多い場合はリストを破棄し、メールで通知します。
<?php
/**
* 1.IPをCIDR表記に変換する
*
* 2.リストの差分がしきい値を超えた場合はリストを破棄
*
* 3.リスト作成の成否をメールで通知する
*
*/
define( 'TEMP_PATH', '/tmp' );
define( 'OLD_CIDR_LIST_PATH', TEMP_PATH . '/ipv4_cidr_02.txt' );
define( 'TMP_CIDR_LIST_PATH', TEMP_PATH . '/ipv4_cidr_03.txt' );
define( 'CIDR_LIST_PATH', TEMP_PATH . '/ipv4_cidr.txt' );
$lists = new SplFileObject(OLD_CIDR_LIST_PATH);
$lists->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
/**
* IPをCIDR形式に変換するスクリプトに渡して
* ファイルへ書き出す
*/
$wfp = fopen( TMP_CIDR_LIST_PATH, 'w' );
foreach( $lists as $list ){
// IPのrangeの取得
$j = explode( "\t", $list );
$country = $j[0];
$ip_min = $j[1];
$ip_max = $j[2];
$split_lists = PlageVersCIDRs( $ip_min, $ip_max );
foreach ( $split_lists as $row ) {
fwrite( $wfp, $country . "\t" . $row . "\n" );
}
}
fclose( $wfp );
/**
* 保存済みの /tmp/ipv4_cidr.txt にあって
* 作成した /tmp/ipv4_cidr_03.txt にないものをカウント
*
* 変更点が多すぎる場合は
* ファイルが正常に取得できていないものとみなし更新しない
* 検査自体は1/2のみで、500の差分がある場合失敗(全体換算で1000)
*
* そしてメールで通知する
*/
if( is_readable( CIDR_LIST_PATH ) ) {
$new_file = new SplFileObject( TMP_CIDR_LIST_PATH );
$new_file->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
$old_file = new SplFileObject( CIDR_LIST_PATH );
$old_file->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
// 保存されたファイルの1/2の行数を取得
$old_file->seek( $old_file->getSize() );
$lines_total = $old_file->key();
$lines_total = $lines_total / 2;
$i = 0;
foreach( $new_file as $val ){
if( $lines_total < $i ){
break;
}
$new_data[] = $val;
$i++;
}
$i = 0;
foreach( $old_file as $val ){
if( $lines_total < $i ){
break;
}
$old_data[] = $val;
$i++;
}
$diff = count( array_diff( $new_data, $old_data ) );
$diff2 = count( array_diff( $old_data, $new_data ) );
// 差分が500以下のときに成功、それ以上のときに失敗コピーしない
if ( $diff < 500 && $diff2 < 500 ){
send_mail( "成功", $diff + $diff2 );
copy( TMP_CIDR_LIST_PATH, CIDR_LIST_PATH );
} else {
send_mail( "失敗", $diff + $diff2 );
}
} else {
send_mail( "新規作成成功", 0 );
copy( TMP_CIDR_LIST_PATH, CIDR_LIST_PATH );
}
/**
* メール送信用
* 成否と差分を記載したメールを送信する
*
* @param string 成功もしくは失敗
* @param int 差分の数値
*/
function send_mail( $flag, $diff ){
mb_language("Japanese");
mb_internal_encoding("UTF-8");
if ( mb_send_mail( "hoge@example.com",
"IPv4のCIDRリスト作成に「" . $flag . "」しました",
"CIDRの作成:" . $flag . "。\nCIDRの差分:" . $diff . "。",
"From: piyo@example.com" ) ){
} else {
echo "メールの送信に失敗しました。";
}
}
/**
* IPの開始と終了の範囲を渡すCIDR形式(サブネット形式)で返す
* オリジナルのものはCIDRで表現できない端数の出る値を丸めていた
* 参照:http://php.net/manual/ja/ref.network.php#75922
*
* 一つ前の処理でCIDRで表現可能な数値に分割しているため
* オリジナルのものはCIDRで表現できない端数の出る値を丸めていたが
* 正確な値で分割が可能となっている
*
* @param int IPの開始点
* @param arr IPの終了点
* @return arr CIDR形式で返す
*/
function PlageVersCIDRs($ip_min, $ip_max) {
$cidrs = array();
$ip_min_bin = sprintf('%032b', $ip_min);
$ip_max_bin = sprintf('%032b', $ip_max);
$ip_cour_bin = $ip_min_bin;
while (strcmp($ip_cour_bin, $ip_max_bin) <= 0) {
$lng_reseau = 32;
$ip_reseau_bin = $ip_cour_bin;
while (($ip_cour_bin[$lng_reseau - 1] == '0') && (strcmp(substr_replace($ip_reseau_bin, '1', $lng_reseau - 1, 1), $ip_max_bin) <= 0)) {
$ip_reseau_bin[$lng_reseau - 1] = '1';
$lng_reseau--;
}
$cidrs[] = long2ip(bindec($ip_cour_bin)).'/'.$lng_reseau;
$ip_cour_bin = sprintf('%032b', bindec($ip_reseau_bin) + 1);
}
return $cidrs;
}
|
これで「tmp/ipv4_cidr.txt」というIPv4の国別リストが作成できました。
mb_send_mail()のhoge@example.comとpiyo@example.comの部分は環境に合わせて変更してください。
ファイル作成の成否を決める差分のしきい値ですが、全体の1/2が500行異なる場合に失敗と判断しています。(全体からすると1000行)
この部分は実際に運用する際に非常に大切な部分です。リストの取得はほとんど失敗しませんが、100回に1度程度の割合で失敗することがあります。中途半端なリストを元にiptables等でアクセス制御すると大事故に繋がります。例えばコンソールでの接続は日本のIP限定としていた場合、リストが正常に取得できていない場合、リモートから接続できなくなります。
更新の頻度ですが、実際に運用してみると、1日に更新される数は100以下が多いようです。ただし、まれに大漁のリストが更新されることがあるので、何度もエラーのメールが届く場合は手動で更新するか、しきい値を見直すなど、調整が必要になります。
リストの半分で判断しているのはメモリの節約のためです。
比較対象のファイルを2つとも配列に入れると200MBを超えたため苦肉の策です。正確性を重視したい場合は全て取得して比較するのが良いと思います。
今考えるとBashのdiffを使って<をカウントすれば簡単でしたね。(もしくはMySQLを利用する)
ipv6_cidr_client_01.php
IPv6のリストはCIDR表記で割り切れる値で割り振られているので、そのまま書き出すだけです。
先程取得したRIRのリストを利用して加工します。
<?php
/*
* IPv6のCIDR形式の割当リストを作成する
* IPv4で取得したリストを利用する
*
*/
define('TEMP_PATH', '/tmp');
define('CIDR_FILTER_PATH', TEMP_PATH . '/ipv6_cidr_01.txt');
$wfp = fopen( CIDR_FILTER_PATH, 'w' );
// ダウンロードしたファイルを全て回す
foreach( glob( TEMP_PATH.'/delegated-*-extended-latest' ) as $filename ) {
$lists = new SplFileObject( $filename );
$lists->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
foreach ( $lists as $line ) {
if( preg_match( '/(arin|ripencc|apnic|lacnic|afrinic)\|[A-Z]+\|ipv6/', $line ) ) {
$rows = explode( '|', $line );
$country = $rows[1]; // 国別コード取得
$ip = $rows[3]; // IPの一番下を指定。後に使う関数用にip2longでIPアドレスを整数型へ変換
$mask = $rows[4]; // IPの一番上を指定。上のIPに範囲を足して1引いたもの
fwrite( $wfp, $country . "\t" . $ip . "/" . $mask ."\n" );
}
}
}
fclose($wfp);
|
ipv6_cidr_client_02.php
後はソートして書き出すだけです。
IPv4と同じようにファイル作成の成否をメールで通知します。こちらはリストの行数が少ないため全て変数に入れて比較しています。
<?php
/*
* 1.リストをソートし使える形式で書き出す
*
* var 1.0.0 2017/5/11
*/
define( 'TEMP_PATH', '/tmp' );
define( 'OLD_CIDR_LIST_PATH', TEMP_PATH . '/ipv6_cidr_01.txt' );
define( 'TMP_CIDR_LIST_PATH', TEMP_PATH . '/ipv6_cidr_02.txt' );
define( 'CIDR_LIST_PATH', TEMP_PATH . '/ipv6_cidr.txt' ); // 書き出すIPリスト
// IPリストをソートしてキーを振り直す
$lists = new SplFileObject(OLD_CIDR_LIST_PATH);
$lists->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
foreach( $lists as $val ){
if ($val === false) continue;
$arr[] = $val;
}
asort($arr);
$wfp = fopen( TMP_CIDR_LIST_PATH, 'w' );
foreach( $arr as $line ){
fwrite( $wfp, $line ."\n" );
}
fclose( $wfp );
/**
* 保存済みの /tmp/ipv6_cidr.txt にあって
* 作成した /tmp/ipv6_cidr_02.txt の差分を調べる
*
* 変更点が多すぎる場合は
* ファイルが正常に取得できていないものとみなし更新しない
*
* そしてメールで通知する
*/
if( is_readable( CIDR_LIST_PATH ) ) {
$new_file = new SplFileObject( TMP_CIDR_LIST_PATH );
$new_file->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
$old_file = new SplFileObject( CIDR_LIST_PATH );
$old_file->setFlags(SplFileObject::READ_AHEAD | SplFileObject::SKIP_EMPTY | SplFileObject::DROP_NEW_LINE);
foreach( $new_file as $val ){
$new_data[] = $val;
}
foreach( $old_file as $val ){
$old_data[] = $val;
}
$diff = count( array_diff( $new_data, $old_data ) );
$diff2 = count( array_diff( $old_data, $new_data ) );
// 差分が1000以下のときに成功、それ以上のときに失敗コピーしない
if ( $diff < 1000 && $diff2 < 1000 ){
send_mail( "成功", $diff + $diff2 );
copy( TMP_CIDR_LIST_PATH, CIDR_LIST_PATH );
} else {
send_mail( "失敗", $diff + $diff2 );
}
} else {
send_mail( "新規作成成功", 0 );
copy( TMP_CIDR_LIST_PATH, CIDR_LIST_PATH );
}
/**
* メール送信用
* 成否と差分を記載したメールを送信する
*
* @param string 成功もしくは失敗
* @param int 差分の数値
*/
function send_mail( $flag, $diff ){
mb_language("Japanese");
mb_internal_encoding("UTF-8");
if ( mb_send_mail( "hoge@example.com",
"IPv6のCIDRリスト作成に「" . $flag . "」しました",
"CIDRの作成:" . $flag . "。\nCIDRの差分:" . $diff . "。",
"From: piyo@example.com" ) ){
} else {
echo "メールの送信に失敗しました。";
}
}
|
こちらもメールの部分は環境に合わせて変更してください。
あとはcronで適当な頻度で実行するだけです。
個人的には一日に一度取得すれば十分だと思います。
以上で/tmpディレクトリに「ipv4_cidr.txt」と「ipv6_cidr.txt」が作成されます。
ipv4_cidr.txtのサンプル
AD 85.94.160.0/19 AD 91.187.64.0/19 AD 109.111.96.0/19 AD 185.4.52.0/22 こんなのがずら~っと13万行ほど |
ipv6_cidr.txtのサンプル
AD 2a02:8060::/31 AD 2a02:c690::/31 AD 2a03:7ac0::/32 AE 2001:67c:2040::/48 こちらは3万6千行ほど |
こうして最新のリストを自前で作成しておけば、サーバが停止しない限り最新のIPリストでアクセスを規制することができます。